A modellers challenge: getting data in front of you that don’t seem to fit any of the standard effect models and PKPD relationships.
Especially in endocrinology, hormonal profiles are rarely in steady-state and vary constantly over time, complicating the application of NLME models. In this post I will discuss 3 degrees of pulsatile profiles on 3 model hormones:
- Circadian rhythm (prolactin)
- Single pulse (melatonin)
- Multiple pulses (growth hormone)
Circadian rhythm (prolactin)
Whether or not a circadian rhythm is truly pulsatile is debatable, but I think it is definitely worth to cover the implementation in this post since a circadian rhythm in the secretion of endogenous compounds occurs not only in endocrinology but in many biological processes in the human body.
Evaluating whether a circadian rhythm is present in your data can be done by visualizing the observations versus the time of day with a smoothing curve. One could also model a steady-state (baseline) model on placebo data and judge the CWRESI over time (also shown below). If a circadian rhythm is present, both figures should show a clear deviation from the 0-line when circadian rhythm plays a role.

The plot above shows the prolactin concentrations over time of day (van Esdonk, M.J., Burggraaf, J., Dehez, M. et al. Quantification of the endogenous growth hormone and prolactin lowering effects of a somatostatin-dopamine chimera using population PK/PD modeling. J Pharmacokinet Pharmacodyn 47, 229–239 (2020). https://doi.org/10.1007/s10928-020-09683-3) in healthy volunteers between 8 am and 10 pm.

So should we spend time on modelling this profile with complex equations? Well, as always, it depends. If the effect size that we are looking at would increase the prolactin concentrations up until 1000 ng/mL, we would not care about that small hover around 10 ng/mL and we can just model it as a steady-state baseline model. However, when the effect size becomes smaller, the correct quantification of the prolactin concentrations over time of day may significantly impact your quantification of the concentration-effect relationship.
If you are interested in modelling the circadian rhyhtm of a variable, you first of all need to have information on the clock time of the samples taken. In your dataset, you could normalize all data around a certain timepoint (e.g. start the time column at midnight) or make sure that you have a separate column in your NM dataset with the clock time ranging from 0 to 24.
Then, we can implement a circadian rhythm in NONMEM by specifying multiple parameters:

where t is the time column or the current model time (specified with T in your differential equations in NONMEM). In this equation, we will estimate the amplitude and the phaseshift parameter. The acrophase parameter can also be estimated but I always fix it to a value that completes a full period within 24 hours to make sure the rhythm does not shift between multiple days (for example in a MAD study).
As can be observed in the CWRESI figure above, the implementation of such a cosine function in a direct effect or a turnover model can account for a high degree of variability and improve the quantification of a drug effect by capturing the secretion over time.
Single pulse (melatonin)
For this example of modelling a single pulse, I use a paper by B. Charles et al., in which they modelled the concentration-time profile of melatonin. The full manuscript can be downloaded from:
https://www.ncbi.nlm.nih.gov/pubmed/18464272
The melatonin profiles they are trying to model looks like this:

As you can see, there is a very low baseline value (during the day) and a single surge of melatonin during the night. Clearly, such a profile cannot be captured by a cosine function and we need to think of something else.
Surge function equation
In their manuscript, they use the following surge function in a turnover model to model the melatonin levels.

As you can observe, we have a turnover differential equation with Kin (zero-order) and Kout (first-order) rate constants. Then, we have a AMP, T0, WID and N parameter. These parameters can be used to model a Gaussian curve with an amplitude, pulse time, pulse width, and an exponent (steepness) of the curve, respectively.
We need to note that the exponent N cannot be estimated but can only be manually changed between 2,4,6,8 etc. and thereby changing the shape of the pulse.
Implementing such a function in a model allows for a highly flexible implementation of a pulse in which we can easily implement variance on the pulse time and amplitude, capturing the inter-individual variability in melatonin release with just a few parameters.
As an example to show you what happens when for example the WID parameter changes from 0.5 to 2 we can use the following R code:
library(ggplot2)
T <- seq(0,12,0.1)
AMP <- 1
Tpeak <- 6
N <- 4
width <- c(0.5,1,2)
df <- data.frame(expand.grid(T=T,AMP=AMP,Tpeak=Tpeak,N=N,width=width))
df$C = 1 + (df$AMP/(((df$T-df$Tpeak)/df$width)^df$N+1))
ggplot(df,aes(T,C))+geom_line()+theme_bw()+ggtitle("Baseline = 1, AMP = 1, Tpeak = 6, N = 4, varying width:")+
facet_grid(~width)+scale_x_continuous(breaks=seq(0,12,2))+ xlab("Time")

As you can imagine, this function can be used in many situations in which you need to model a single pulse in the data. However, when the number of pulses in a single profile are increasing (perhaps 3 or 4 pulses in a single 24h profile) it becomes much more difficult to obtain successful minimization of the parameter estimates due to the high number of parameters that are required.
Multiple pulses (growth hormone)
So lets cover one of the more interesting profiles, growth hormone!
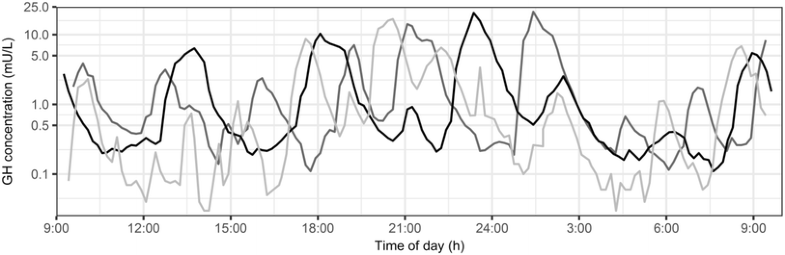
https://link.springer.com/article/10.1007/s10928-017-9526-0
Now this is what I call a pulsatile profile! As you can observe from the image above, there is a large level of intra- and inter-individual variability in the concentration-time profile and this definitely complicates model development when we are interested in quantifying a drug effect on such a profile.
For this example I am self-citing for 100% my own publication in which we investigated a new methodology for the quantification of growth hormone secretion:
https://link.springer.com/article/10.1007/s10928-017-9526-0
As I explained before, estimating all the pulses in NONMEM with the equation that we just discussed for melatonin will result in minimization problems since up to 20 pulses would need to be estimated. However, what cán we do when we have a drug effect on such a profile? Luckily we can borrow methodology a different mathematical concept, called deconvolution:
https://www.sciencedirect.com/science/article/pii/S0076687908038159
With deconvolution, we can estimate, among others, the amplitude and location of the pulses in a profile on an individual level. Then, when we obtain all the pulse locations in a profile, we can incorporate this information in our NM dataset to reduce the number of parameters we need to estimate. Furthermore, this reduces minimization problems since the pulses cannot overlap anymore due to their fixed location in the profile.
So, does this enable us to model growth hormone?
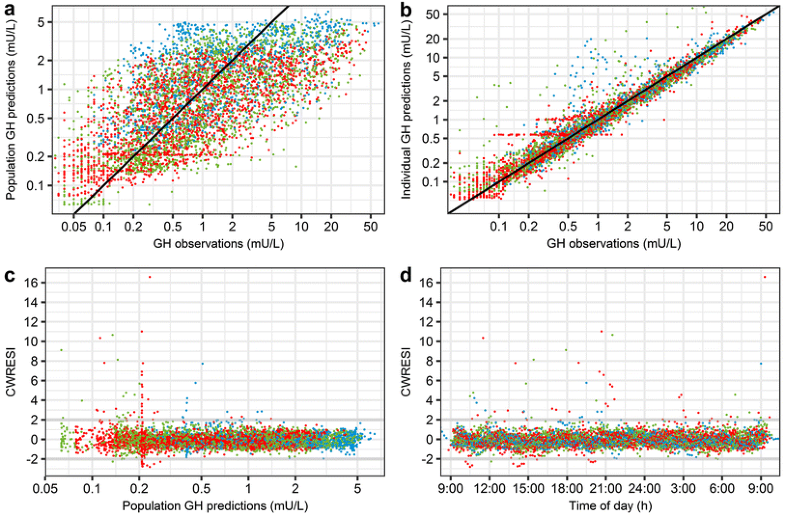
https://link.springer.com/article/10.1007/s10928-017-9526-0
Yes! However, as you can see in the figure above, there is huge variability in the population predictions. This makes sense because growth hormone data in general is highly stochastic. However, by inclusion of some eta’s on the population parameters, we have a scatter close to the line of unity in the individual predictions, indicating that the model is able to capture the individual profiles!
Additionally, during a simulation study, we have shown that we can re-estimate a hypothetical drug effect on such a pulsatile profile and we are currently in the process of publishing the application of this method on real-world phase 1 clinical trial data.
Of course, this is just a quick glimpse into the basics of this methodology which is described in more detail in the publication. However, I hope that this post has provided you with some insight in the different methodologies that are out there to point you in the right direction of modelling your pulsatile profile.
COMMENT
Any suggestions or typo’s? Leave a comment or contact me at info@pmxsolutions.com!